Two years ago, Mark Zuckerberg revealed that teaching Meta's Llama model with code significantly improved its reasoning ability. It enabled smaller models like Llama 3 to outperform larger models like Llama 2. The industry took notice and every leading AI lab began teaching models to code. This essay explores why learning code helps models reason.

In the second part, we'll explore how models went from learning code to generating code as a reasoning tool. While doing so, they continue using the transformer architecture built for natural language leading to accuracy loss.
In the third part, I propose graph transformers for code generation. Current transformers excel at word sequences but struggle with code's hierarchical structure (packages containing classes containing functions containing expressions and datastructures). Graphs naturally represent this hierarchy.
Why Teaching Code Improves Reasoning in AI
Consider a simple problem of placing a 13-foot ladder to reach exactly 12 feet up a wall:
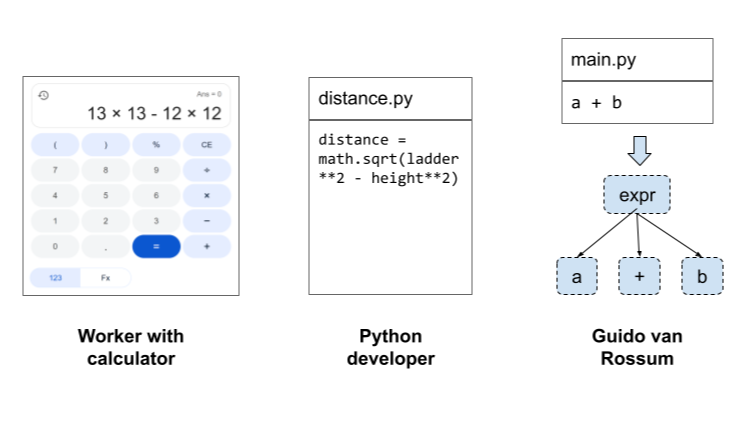
- Users work with data: A maintenance worker will climb the ladder with measuring tape, mark 12 feet on the wall, then drags the ladder until it hits the mark. This approach works directly with physical data i.e. measuring, positioning, adjusting. It's concrete, reliable, but inefficient.
- Engineers work with metadata: An engineer will apply the Pythagorean theorem: √(13² - 12²) = 5 feet. They will place the ladder base 5 feet from the wall, and it will reach exactly 12 feet. The engineer works with abstract relationships such as variables, equations, formulas that generalize across all similar problems. One calculation replaces countless physical measurements.

This is why users use spreadsheets for repetitive tasks. Spreadsheets provide an intuitive way to work with data while writing formulas that can be applied to consecutive rows. You see the results immediately as you work.
Software engineers, on the other hand, think with algebra (i.e., as metadata). They declare variables (ladderLength, reachHeight), apply operations, and assign the result to distance_from_wall. They express this logic in an IDE without seeing any data. Only at runtime do they apply actual values and check if their logic works correctly.
This ability to abstract logic from data is what separates software engineers from users. It's also what distinguishes models trained primarily on text (like early GPT-3) from those trained heavily on code (like GPT-5). This is why Llama 3, trained on code, outperformed the larger Llama 2 in reasoning. It learned to operate at the metadata level by thinking in terms of variables and functions rather than concrete values. Training on code isn't about learning syntax; it's about learning to abstract. When trained on Python code, the model's hidden states learn to represent code structure as variables, types, control flow rather than just word patterns.
Reasoning is the ability to climb this abstraction ladder: from manipulating concrete data to manipulating the code that generates the data. This abstraction jump created a wave of AI coding tools like Cursor, Replit. But then progress stalled. Instead of improving code understanding, models started outsourcing to external Python interpreters.
Tool use masks architectural limitation
When you ask GPT-5 to count the number of letters in this essay, it generates python code and executes it in a sandbox to find the answer (
see code + results). On the surface, it looks like GPT5 performs better than GPT4, but if you force it to use pure reasoning mode, it falls flat:

This was quite visible in GPT5’s FrontierMath performance during its launch announcement:
- Tool-use mode: 26.3% accuracy
- Pure reasoning mode: 13.5% accuracy
The 2x improvement shows GPT-5 learned when to delegate. It is a clever engineering solution. But it hides the problem in AI research: code generation hasn't improved much. The model got better at recognizing when to call Python, not at understanding code structure. This is why vibe coding tools that were hoping for a dramatic improvement in code generation were disappointed.
There are two fundamental issues that cause this plateau:
1. Tokenization Fragmentation
Ask GPT3 to count the letter "r" in "strawberry," and it often fails. Not because it can't count, but because tokenization splits the word into ["straw", "berry"] or ["str", "aw", "berry"]. A variable named ladderLength gets split into ["lad", "der", "Length"], forcing the model to reconstruct meaning from fragments it never sees as whole. Modern tokenizers mitigate this, but the broader architectural issue remains, as we see in counting the letters in this essay.
2. Structure Flattening
Code is hierarchical: functions contain blocks, blocks contain statements, statements contain expressions and datastructures. Current transformers linearize this into flat token sequences:
Your python code:
math.sqrt(ladderLength*ladderLength - reachHeight*reachHeight)
Becomes:
["math", ".", "sqrt", "(", "ladder", "Length", "*", "ladder", "Length", "-", "reach", "Height", "*", "reach", "Height", ")"]
The tree structure has to be inferred from token proximity rather than explicit relationships. The model must reconstruct hierarchical relationships as hidden states, often called the
Neuralese.
Graph Transformer: Mind Map for AI
Unlike natural language, code is compiled into a parse tree (AST) that can be executed by an interpreter. Graph transformers are a natural fit for this structured representation. But code is the intermediate step for reasoning tasks. Users type in English and expect conversational responses. How do we bridge this gap?
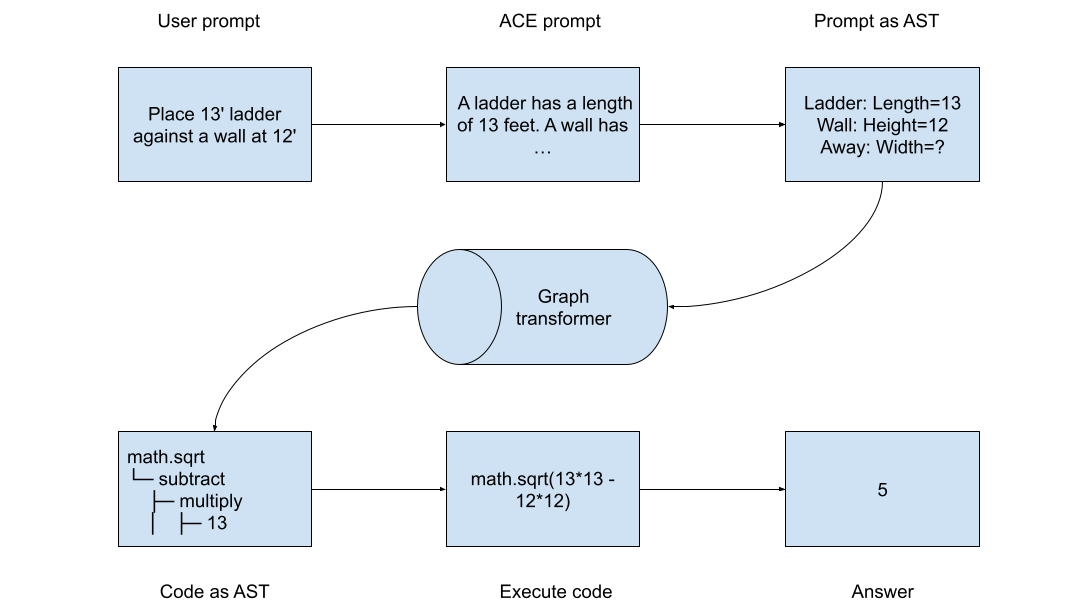
The answer: a three-part pipeline that preserves structure throughout.
Part 1: Parse User Prompts into Structured Graphs
User prompt is in natural language such as english which is ambiguous and might have spelling/grammatical mistakes. LLMs rewrite this into proper prompts to be effective. Instead of rewriting into english, we can rewrite them into Attempto Controlled English (ACE), a precisely defined subset of English with deterministic grammar. Think of it as TypeScript for natural language. Just as TypeScript adds type safety to JavaScript, ACE adds structural precision to natural language. Every sentence has exactly one structural interpretation.
Our ambiguous English prompt:
Place a 13 foot ladder against a wall at 12 feet
Becomes unambiguous ACE:
A ladder has a length of 13 feet. A wall has a height of 12 feet. Calculate the distance from the wall where the ladder base must be placed such that the ladder top reaches the wall height.
This can be parsed into graphs where nouns like ladder, length become nodes and verbs like has, calculate become edges.
Part 2: Parse Code as Abstract Syntax Trees
Instead of treating code as a linear token sequence, we parse it into an AST that preserves hierarchical structure:
Our Python code:
math.sqrt(ladderLength*ladderLength - reachHeight*reachHeight)
Becomes parse tree:
math.sqrt
└─ subtract
├─ multiply
│ ├─ ladderLength
│ └─ ladderLength
└─ multiply
├─ reachHeight
└─ reachHeight
We can now train the graph transformer with ACE prompt as the input graph and python parse tree as the output graph.
Part 3: Convert ACE prompt into code during inference
During inference, instead of predicting tokens sequentially, graph transformers predict nodes structurally. The model asks "what operation does sqrt take as input?" not "what word comes after 'sqrt'?" This reduces the accuracy loss that happens when rebuilding structure as hidden states. Parse tree makes the structure explicit and avoids loss:
- No tokenization fragmentation: ladderLength stays whole
- Structure preserved: Parent-child relationships explicit
- Type-aware generation: Model knows what kind of node can go where
Why This Solves the Accuracy Problem
Remember the FrontierMath results:
- GPT-5 with external Python: 26.3% accuracy
- GPT-5 pure reasoning: 13.5% accuracy
The 2x gap exists because Python execution is deterministic (100% accurate) while GPT-5's code generation is lossy (fragments variables, flattens structure). It reconstructed variables and hierarchical relationships implicitly as hidden states i.e. in neuralese. But that's wasted potential. We trained the most sophisticated pattern-recognition system ever built, then made it spend half its compute reconstructing parse trees, which compilers can do at zero cost. Graph transformers let neuralese do what neuralese is for i.e. understanding the meaning of the user prompt and providing solution as code, not recovering structure of the code.
Interpretability comes as a side effect of structured graph. Parse tree of the generated python code will follow python grammar instead of a hotchpotch grammar cooked up inside neuralese. If the chain of thought is generated as graph, it will mimic how humans think with mind maps.
Implementation Challenges
This architecture requires solving two key problems.
- Graph Attention Scaling
Graph transformers aren't new. They're so computationally expensive that they are not practical for LLMs. But LLMs moved from generating natural language for chatbots to code generation for reasoning. So, this investment may now be worthwhile.
We can also use a fallback to see if graph produces better results in the current transformers. We can train them with parse tree with modified attention bias. For example, we can increase attention bias for parent/child/sibling nodes and reduce it for distant nodes. If this works, we can then invest in graph transformers for even better results. - ACE Translation
Converting natural English to ACE with high accuracy is a big challenge. It is a 20+ year old project used mainly in academic circles, and lacks a large public corpus for training. Other structured representations like AMR (Abstract Meaning Representation) have more active research communities but face similar data constraints. However, LLMs already do prompt rewriting to improve clarity. Redirecting this effort toward ACE-based (or AMR-based) prompt rewriting could offset the additional labeling cost.
If the initial cost of this migration is high, we can use flat tokens as input while outputting graphs with modified attention as an incremental step toward full graph transformers. Some research explored this in the pre-LLM era, and revisiting it in the reasoning model era could provide the incremental validation needed to justify investment in ACE based prompt rewriting.
Beyond Metadata: The Path to AGI
When DeepMind researchers trained AlphaGo on data from Go games, it became good at Go, but its progress stalled. So, they trained a new model called AlphaZero on all games. It not only became better at Go, it also automatically became better at Chess without training. This is again because of the meta understanding of the game rules. Now they are exploring if the next version of AlphaZero can invent a new game.
This is similar to how we move up the value chain from user to developer to language creator. As users, we use calculators (data tools) to solve specific problems like finding ladder distance. When we learn to code, we abstract these tasks into code (metadata), using programming languages like python. Once we are very good at coding, we dream about creating new language like python using parser generators like PEG (meta-metadata).
If this analogy holds for AI, will giving them PEG grammar of python and javascript help them create a new language? Will it know which parts of a language are good and combine them to create a new language e.g. readability of python and flexibility of javascript? Or will they never understand developer taste?
If we revise OpenAI’s levels framework using our meta framework, we get:
| Level | Math | Coding | Games | AI |
|---|
| Data | Worker measuring with tape | User using your app | AlphaGo training on Go games | LLM answering questions
(Level 1 - chatbot) |
| Metadata | Engineer using pythoream theorem | You coding that app in python | AlphaZero playing all games | Reasoning model writing code
(Level 2 - reasoner) |
| Meta-metadata | Pythagorus discovering the theorem | Guido creating python with PEG | Next AlphaZero creating a new game | AGI discovering theorem, language, game
(Level 4 - innovator) |
| Specialized for math | Specialized for coding | Specialized for games | Generalized across disciplines |
Before LLMs, we doubted if AI could ever create art or poetry that understands human taste. Yet here we are. Perhaps the same will happen for programming languages and theorems. After all, intelligence isn't just about solving problems. It's about discovering the hidden rules that create them. Maybe, it will find the hidden rules across meta-metadata like pythagoren theorem, python, Go that we haven't discovered yet. And that might be the path to AGI.
Note:
This is a summary of my essays over the last 2 years. Here are the relevant ones:
For more details, please read them.

1 likes
0 comments
Like
Add your comment