
One of the perennial debates I have with my dad is how unhealthy fruit juice is compared to whole fruit. Bottled juices from supermarkets often strip away fiber and vitamins, leaving mostly sugar. Even when these drinks are fortified with vitamins and labeled to resemble real fruit, they’re nowhere near as healthy. That’s why NutriScore - an algorithm designed to rate food healthiness doesn’t just analyze ingredients; it begins by determining the category of the food. Fruit juice and whole fruit are scored differently.
This classification step is at the heart of Neartail’s search engine for healthy food. Our system uses a series of fine-tuned AI agents to compute NutriScore and rank food items accordingly. Here's how the workflow is structured:
Ingredient Extraction Agent: Scrapes nutritional data (sugar, fat, fiber, etc.) from product webpages.
Estimation Agent: Fills in missing values using probabilistic guesses based on similar products.
Classification Agent: Categorizes the food item (e.g., General Food, Red Meat, Beverage, Cheese).
Scoring Agent: Applies NutriScore calculation tailored to the classified category.
It sounds simple, but we quickly encountered what we call the butterfly effect - a phenomenon where small upstream mistakes trigger large, downstream consequences.
Why the Butterfly Effect Happens
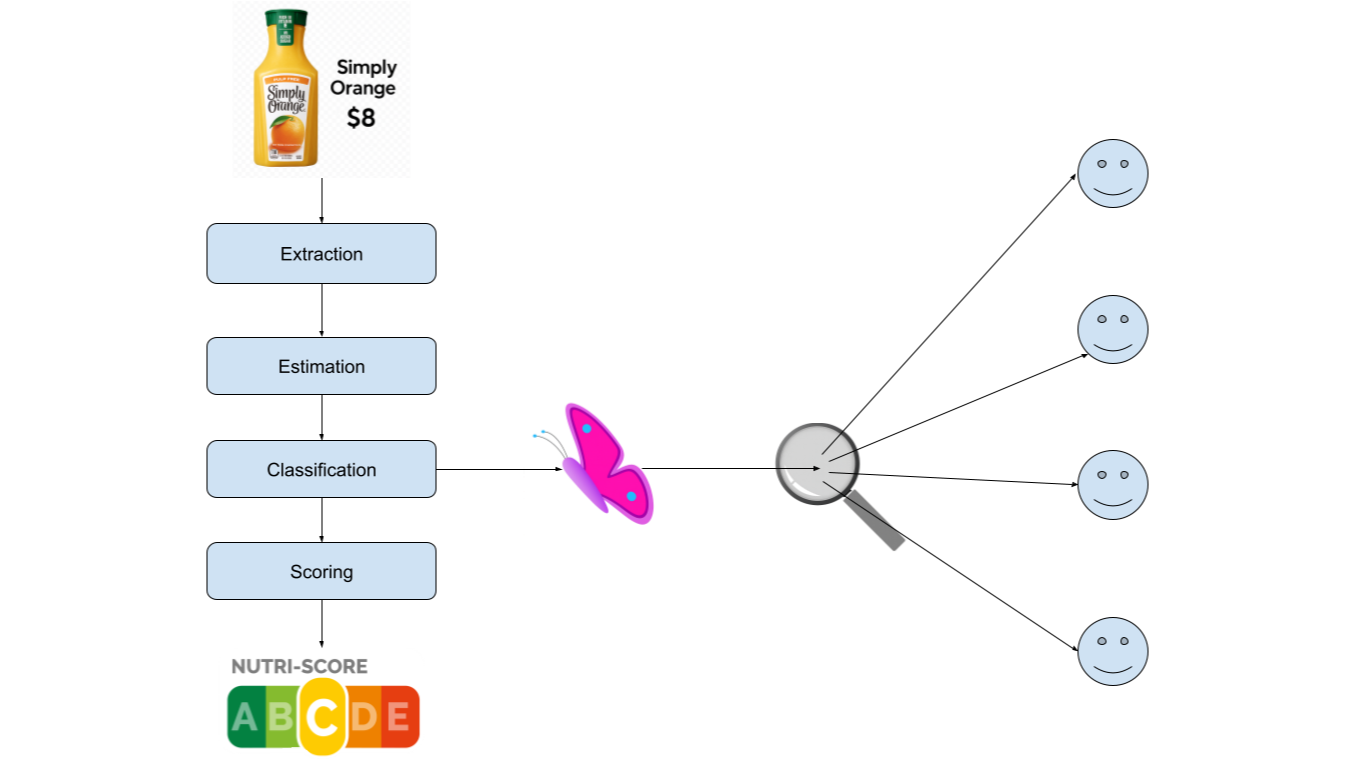
- Misclassification in a Critical Step:
In agentic workflows, errors in critical steps - what we call "butterfly steps" - can change the entire outcome. For example, if our system misclassifies a sugary fruit juice as a general food rather than a beverage, the scoring becomes lenient. Since beverages are penalized more harshly for sugar, the misclassification leads to an inflated health score. The result? An unhealthy product appears healthy. - Amplification Through Repetition:
The second cause is repetition. Consumer workflows (e.g., trip planning) are often one-off. Prosumer workflows (e.g., generating leads) may be repeated occasionally. But B2B workflows - like extracting financial data from quarterly reports - run daily. A small classification bug in these scenarios can corrupt thousands of records or mislead entire business dashboards.
How We Contain the Butterfly Effect
We use multiple guardrails to keep these errors in check:
Finetuning for Butterfly Steps (using Promptrepo): For high-risk steps like food classification, we rely on finetuned models rather than prompting. We also enforce strict output schemas - like predefined enums for food categories.
Field-Level Confidence Scoring (using @promptrepo/score): We convert logprobs into 0 - 1 confidence scores. For example, if the system is only 0.62 confident that coconut water is a beverage, we flag it for review.
Human-in-the-Loop Review: Low-confidence values are escalated to business owners for manual review. Their corrections feed back into the system, continuously improving reliability.
These layers help us build agentic systems that are not only intelligent but trustworthy. And this isn't limited to food classification. Whether it’s healthcare, finance, or legal tech, systems that rely on early classification are prone to similar ripple effects. Left unchecked, small errors can scale rapidly. Guardrails are not optional - they're essential.
The Future of Agentic Workflows
Agents will evolve based on how frequently they are used and how critical their outcomes are. Consumer agents will prioritize usability, with lightweight confirmation before executing tasks. Prosumer agents will blend flexibility and ease of use through a no-code UI. Enterprise agents will demand full customization and fine-tuning of each workflow step.
User Type | Past | Future | Workflow steps | Butterfly Step |
|---|---|---|---|---|
Consumer | Google + Human | Agentic Bot (Manus) | Confirm | - |
Prosumer | No-code Tool | Config-based Agent + UI (Google ADK) | Edit | Prompting |
Business | SaaS | Code-based Agent (Google ADK) | Create | Finetuning |
1. Manus-like, Synthesized agents for consumers
Workflows are synthesized automatically.
Internals are opaque, but chain-of-thought reasoning provides some transparency.
Ideal for lightweight, one-time decisions where usability matters most.
2. Config-Based No-Code agents for prosumers
Users define workflows visually through configuration.
Balances ease of use with the ability to review and modify the workflow.
Ideal for moderate-frequency use cases with some business risk.
3. Domain-Tuned Code-Based agents for businesses
Developers write and orchestrate workflows in code.
Precision and fine-tuning are essential.
Suited for high-frequency, high-stakes applications that demand auditability.
Summary
"AI is the most significant change in programming. For the first time, logic is transitioning from deterministic to probabilistic."
I tweeted this nine years ago, expecting two big changes:
Probabilistic algorithms - like classification and extraction - would be embedded into everyday code, just like deterministic algorithms such as sorting.
But we'd treat them differently: always checking confidence levels and involving humans when uncertainty arises.
The first change happened. The second didn’t. Today, we use probabilistic AI to generate deterministic code in the name of "vibe coding," deploying them to thousands of users without understanding how confident the AI is in its outputs.
Would you let an AI build a diet plan for cardiac patients using a model that's only 75% confident in food classification? And yet, we allow similar risks in SaaS workflows every day.
As we move from AI as an assistant to AI as a decision-maker, we must identify the butterfly steps - finetune them, check confidence scores, and ask whether a human should weigh in. Otherwise, we risk the other prediction I made:
"AI takeover won't be like Skynet, but it might still have the same effect. It'll start with small improvements to #UX by suggesting what user wants. But as accuracy increases, users will get hooked & delegate all decision making to #AI."
0 likes
0 comments
Like
Add your comment