
In my last post, I argued that code generation is not only used by AI coding tools like Cursor. It is the kingpin behind reasoning and all that is built on top of it (from agentic AI to AGI itself). For example, if you ask AI how to position a 13-foot ladder to reach exactly 12 feet up a wall, a reasoning model like GPT-5 uses the pythagorean theorem to calculate the answer: 5 feet from the wall. There are two ways it can do this:
- Code generation mode (Tool use): Generate math.sqrt(13*13 - 12*12) and use Python as a tool to run it and return 5.
- Pure reasoning mode (No tool use): If you ask GPT-5 not to use tools like Python, it will use internal reasoning to calculate the same.
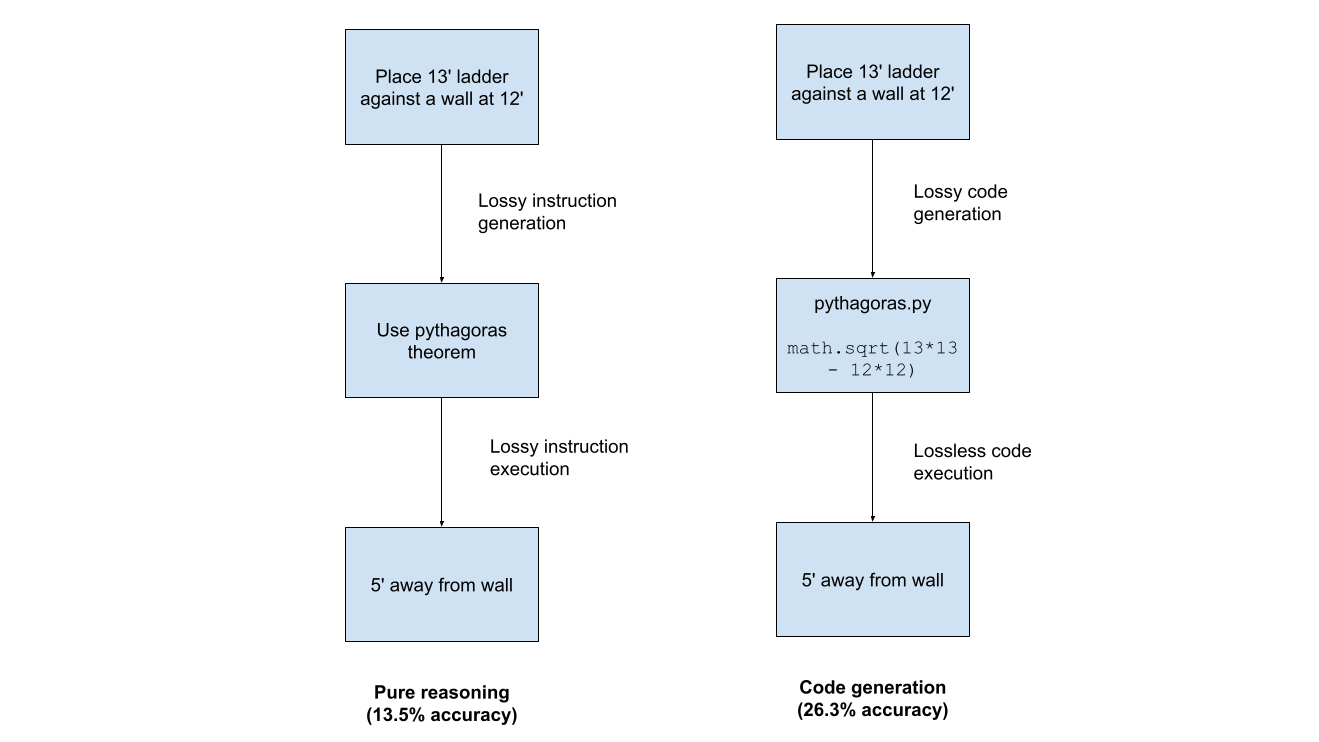
Pure reasoning uses statistical algorithms, so it isn't 100% accurate like Python. As tasks get more complex, errors compound dramatically. On FrontierMath (a benchmark of expert-level mathematics) pure reasoning achieves only 13.5% accuracy vs. 26.3% for code generation [1]. That's a 2x difference.
This reveals the core bottleneck: to improve reasoning, we need to improve how accurately models convert natural language into correct code. If you improve code generation for Cursor, you automatically improve reasoning in ChatGPT.
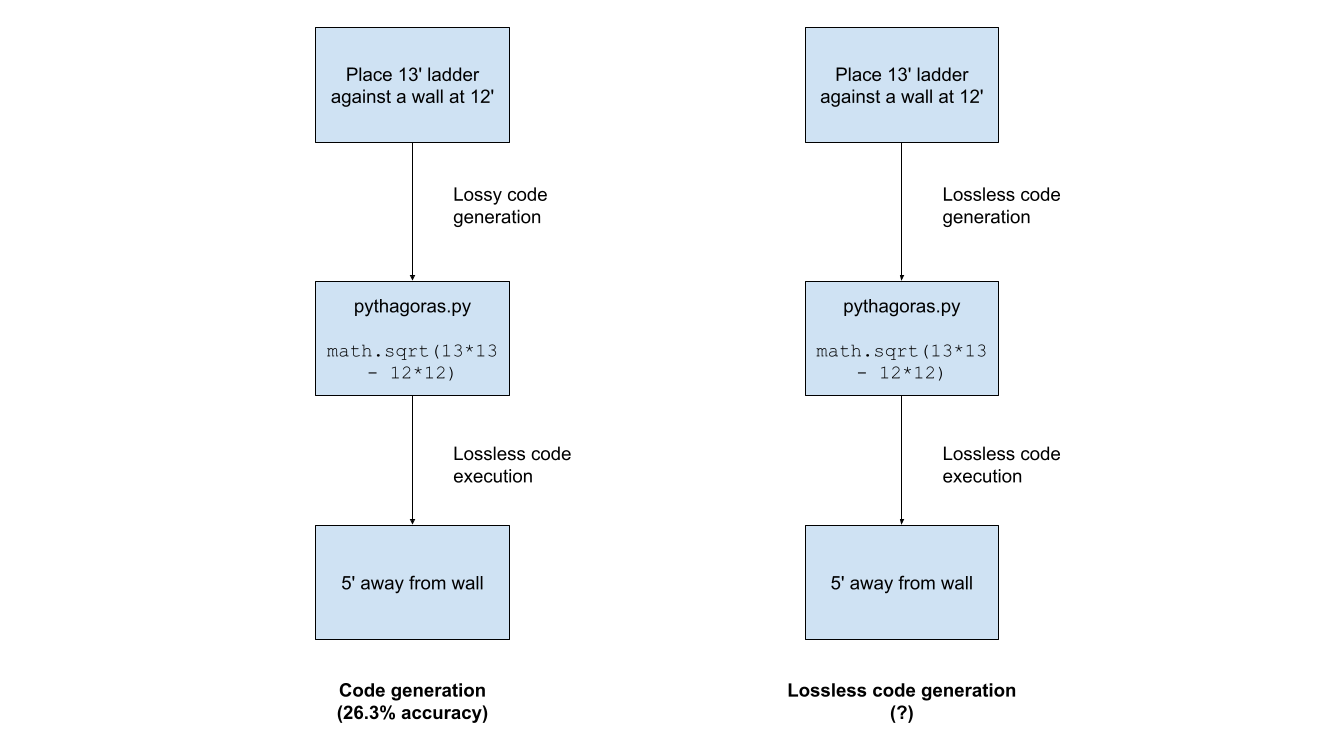
So the question becomes: how do you improve code generation accuracy? How do you convert place a 13' ladder against a wall at 12' into math.sqrt(13*13 - 12*12) with high reliability?
This article explores an approach by:
- Parsing place a 13' ladder against a wall at 12' into an input graph
- Parsing math.sqrt(13*13 - 12*12) into an output graph
- Using graph transformers to convert the input graph into output graph
1. Parsing User Prompts into Input Graphs
Problem: Tokenization Fragmentation
Ask an AI model to count the letter "r" in the word "strawberry," and it will often get it wrong. This isn't a bug. It's a fundamental architectural limitation.
The problem occurs during tokenization, where text is split into chunks. Instead of treating "strawberry" as a single unit, the model splits it into ["straw", "berry"] or ["str", "aw", "berry"]. The model can count "r"s within each fragment, but not across the boundaries between them.
Modern tokenizers keep common words like "strawberry" as single tokens, but this fails with user-defined variables. For example, a variable named "ladlen" (short for "ladder length") gets split into ["lad", "len"], forcing the model to reconstruct meaning from fragments.
Solution: Prompt Rewriting Using ACE
Instead of splitting user prompts into sequences of tokens, we can parse them as trees of sentences, where sentences in turn contain words. However, parsing conversational English is error-prone and computationally expensive. Ambiguity is everywhere, and users may make mistakes while entering prompts.
LLMs already rewrite prompts to correct mistakes and improve efficiency. Instead of just correcting mistakes, why not rewrite them into a structure that's directly parseable into a graph?
Attempto Controlled English: TypeScript for English
Attempto Controlled English (ACE) is a precisely defined subset of English with deterministic grammar. It's like TypeScript for English. Just as TypeScript adds type safety to JavaScript, ACE adds structural precision to natural language. Every sentence has exactly one structural interpretation.
Compare ambiguous English to ACE for our ladder problem:
Ambiguous English:
Place a 13 foot ladder against a wall at 12 feet
ACE (unambiguous):
A ladder has a length of 13 feet. A wall has a height of 12 feet. Calculate the distance from the wall where the ladder base must be placed such that the ladder top reaches the wall height.
The ACE version explicitly states:
- What entities exist (ladder, wall)
- Their properties (length: 13 feet, height: 12 feet)
- What to calculate (distance from wall)
- Constraints (ladder top reaches wall height)
Every ACE sentence maps to a Discourse Representation Structure (DRS), a formal logical representation that converts directly to a graph.
Note: Users never write ACE themselves. Just as LLMs already rewrite prompts internally for better results, the system would translate natural English to ACE behind the scenes.
2. Parsing Code into Output Graphs
Problem: Treating Hierarchical Structures as Linear Sequences
Natural language can flow linearly: one word naturally follows another. But code is fundamentally hierarchical. Functions contain blocks, blocks contain statements, statements contain expressions. That's why we parse code into Abstract Syntax Trees (ASTs).
Current transformers treat code like text: they linearize the AST into a flat token sequence, then predict the next token. This forces the model to reconstruct the tree structure probabilistically in its hidden states.
Consider the ladder problem from our intro. A user asks: place a 13' ladder against a wall at 12'. The correct code should be:
math.sqrt(ladderLength*ladderLength - reachHeight*reachHeight)
But model sees as:
["math", ".", "sqrt", "(", "ladder", "Length", "*", "ladder", "Length", "-", "reach", "Height", "*", "reach", "Height", ")"]
Solution: Parse Code as AST Tree
Instead of treating code as a linear sequence, we can parse it into an AST tree that looks like this:
math.sqrt└─ subtract├─ multiply│ ├─ ladderLength│ └─ ladderLength└─ multiply├─ reachHeight└─ reachHeight
The sequence model must reconstruct this tree from flat tokens. It's like asking someone to understand a family tree by reading their last names, sex, and age. The relationships exist, but you have to infer them, often not so accurately. AST tree makes relationships explicit:
- sqrt takes one argument: the result of subtraction
- Subtraction operates on two multiplications
- Each multiplication squares a variable
The structure is no longer implicit in token proximity. It's explicit in the tree edges.
3. Converting Input Graphs to Output Graphs
Problem: Transformer optimized for natural language
Current transformer architecture is built for the natural language where linear sequence of words (i.e. tokens) is produced as output. This is fine for writing essays. But, for producing structured information like code, it has to:
- Reconstruct intended meaning from fragmented tokens
- Infer hierarchical code structure
- Generate tokens that happen to form valid syntax
Solution: Graph transformer optimized for programming language
Instead, we can use graph transformers:
- Input: A graph where nodes are concepts/entities and edges are relationships
- Processing: Attention operates over graph structure, not linear sequence
- Output: A new graph structure (the AST)
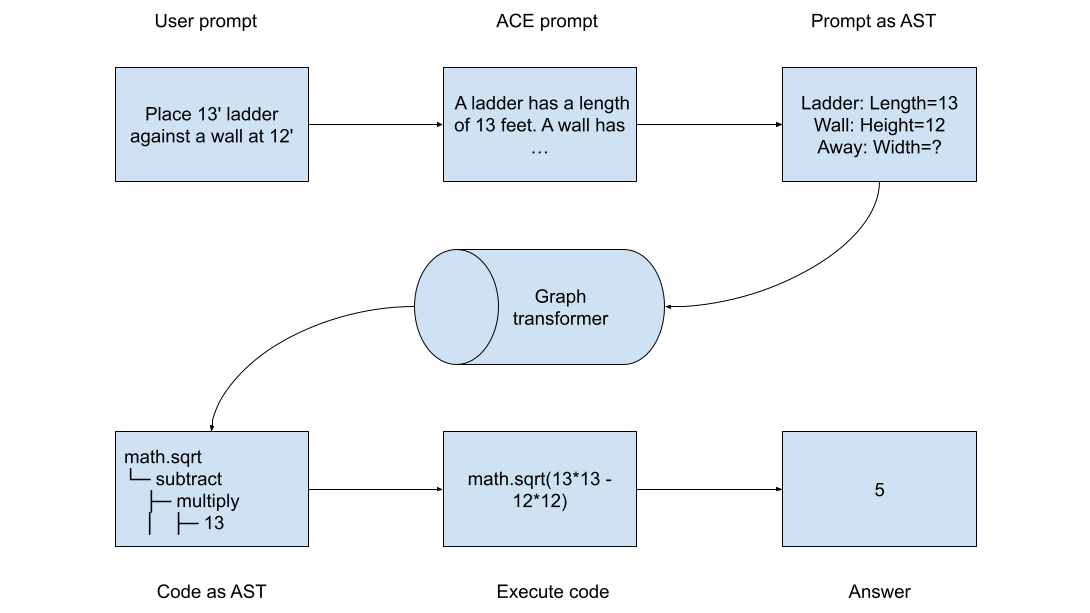
Advantages:
- No token fragmentation: "ladlen" remains a single node, not ["lad", "len"]
- Structure preserved: Tree hierarchies maintained as explicit parent-child edges
- Predict nodes, not tokens: Generate the next node in the tree structure
The graph transformer learns to map problem structures to solution structures while preserving hierarchical relationships.
Expected Benefits
1. Accuracy Improvement
For mathematical reasoning (FrontierMath):
- Pure reasoning mode: 13.5%
- Current code generation: 26.3%
- Lossless generation: 35% - 40% [3]
For business logic (billing, inventory):
The output graph should resemble object-oriented structures rather than functional math. For example, a billing system would generate: Order <contains> OrderItems with Order.calculate() method to compute total from line items. Success metric: compare graph-based accuracy against token-based generation for business datasets like CSV, JSON and RDBMS where relationships between entities matter.
For relational reasoning (reversal curse):
Current models fail at symmetric reasoning. GPT-4 answers "Who is Tom Cruise's mother?" correctly 79% of the time, but only 33% for "Who is Mary Lee Pfeiffer's son?" Graph-based representations should improve the reverse direction to >50% by making relationships bidirectional by default.
2. Interpretability as a side benefit
Code generation provides built-in interpretability. Since code execution is deterministic and 100% accurate, we can:
- Inspect the generated code directly
- Ask the LLM to explain the logic in plain English
- Use the code as an intermediate reasoning step
This makes the model's reasoning process transparent and verifiable. It's a significant advantage over opaque LLM reasoning.
3. Cost Reduction: 4-10x savings
Deterministic code execution is orders of magnitude more efficient than probabilistic token generation. So, for simple math, tool-based code generation is already 4-10x cheaper than pure reasoning [2]. However, current systems still use probabilistic (lossy) code generation. With lossless code generation via graph transformers, we should expect even greater improvement.
Implementation
Challenges
1. Prompt rewriting from English to ACE english
LLMs already rewrite vague or ambiguous prompts entered by user into effective prompts. This is why they can “understand” poorly phrased instructions or fix user errors on the fly. But this is fuzzy but forgiving. They tolerate typos, slang, mixed grammar, and context drift. ACE parsing is strict. A missing determiner or ambiguous clause can cause parsing failure. Users might have to fix ambiguity before reasoning can proceed.
Controlled languages like ACE are good for facts, relations, and logic. But they struggle with tone, irony, or indirect intent (“Can you maybe check this quickly?”). It would flatten them away or need extra metadata to preserve them.
2. Graph transformer trained on ACE as input and AST as output
This is the biggest challenge of all. There are several challenges such as:
Graph Structure Complexity
Variable graph sizes: Unlike fixed-sequence transformers, input graphs (ACE representations) and output graphs (ASTs) have highly variable sizes and topologies. The model must handle graphs ranging from simple expressions to complex nested structures.Predicting the next node in a partially-constructed AST is fundamentally different from predicting the next token. The attention mechanism must learn which edge types are relevant for different reasoning steps.
Training Data Scarcity
No large-scale ACE-to-code dataset exists: You'd need millions of examples of:
- Natural English prompts
- Their ACE translations
- Corresponding code solutions
- All three aligned and verified for correctness
Current datasets are sequence-based: Existing code generation datasets (like HumanEval, MBPP, CodeContests) provide text→code pairs, not structured graph representations. You could generate ACE→code pairs synthetically, using the prompt rewriting mentioned above. The manual verification will cost still be high.
Computational Challenges
Graph attention is expensive: Standard transformer attention is O(n²) for sequence length n. Graph attention over arbitrary topologies can be even worse, especially with heterogeneous edge types.
Message passing iterations: Graph transformers typically require multiple rounds of message passing to propagate information across distant nodes. This increases computational cost.
3. Supporting conversations with reasoning
Real worlds conversations are not an either/or choice between casual conversation and reasoning. They are combined together. For simple conversations that doesn't require reasoning, it can switch to regular model in mixture of experts (MoE) architecture. But, there will be conversations with relational reasoning like the Tom Cruise example we saw earlier. These graph transformers have to be trained on ACE as input to produce ACE as output and then ACE output has to be converted back into natural english, so that the conversation looks natural. This also involves significant amount of effort in training.
Why Now?
Graph-based approaches aren't new. GraphCodeBERT incorporated data flow graphs but still processes tokenized sequences. They use graph structure only to guide attention. We're proposing native graph architectures that operate directly on AST and ACE structures, predicting next nodes rather than next tokens. So far, the barriers have been:
- Scaling seemed to work – more compute kept improving sequence models
- Natural language parsing was unreliable – ACE provides a solution
- The field optimized for fluency over precision – creative writing doesn't need perfect structure
Now that code generation accuracy has plateaued in practical use (not theoretical benchmarks), structured graph provides a promising path for improvement. But does the potential improvement justify the engineering investment? Yes, if you consider that the nature of intelligence is meta:
- Understanding data from what you read and recalling them is memorization. This is what GPT3 does.
- Understanding metadata such as pythagorean theorem and applying it to data such as ladder problem is reasoning. This is what GPT5 does.
- Understanding meta-metadata such as ANTLR grammar and creating a new programming language is invention. That's what AGI should do.
So, the linear tokenization that worked for memorization, may not be best path forward. Structured graphs, instead, might be the right path for reasoning and AGI.
Conclusion: A Return to Deterministic Foundations
Our approach is deliberately narrow: an antithesis to scaling laws and general intelligence. Rather than throwing more compute at the entire problem, we focus on making compute efficient for a specific bottleneck in the reasoning chain:
AGI > Reasoning > Tool Use Mode > [Code Generation]
It's "do things that don't scale, but for AGI." By focusing on code generation, a tiny but critical part of the pipeline, we can address two fundamental sources of loss:
- Tokenization fragmentation - "strawberry" becomes ["straw", "berry"], forcing reconstruction from pieces
- Treating hierarchical structures as linear sequences - Code ASTs flattened into tokens, forcing probabilistic inference of tree structure
Graph transformers that predict next nodes (not next tokens) on structured representations (ASTs, ACE graphs) address both sources of loss simultaneously.
One might object: doesn't specializing transformers for code-based reasoning narrow their scope, contradicting the goal of general-purpose intelligence? But even humans are specialized as creative and analytical people. LLMs can continue to be the general intelligence for creative tasks. But they should not be forced to perform deterministic tasks that are not their natural strength. We have programming languages that have evolved over decades to be accurate, interpretable, and verifiable. We shouldn't abandon this foundation. We should build on it, using neural networks where they excel rather than forcing them to do everything.
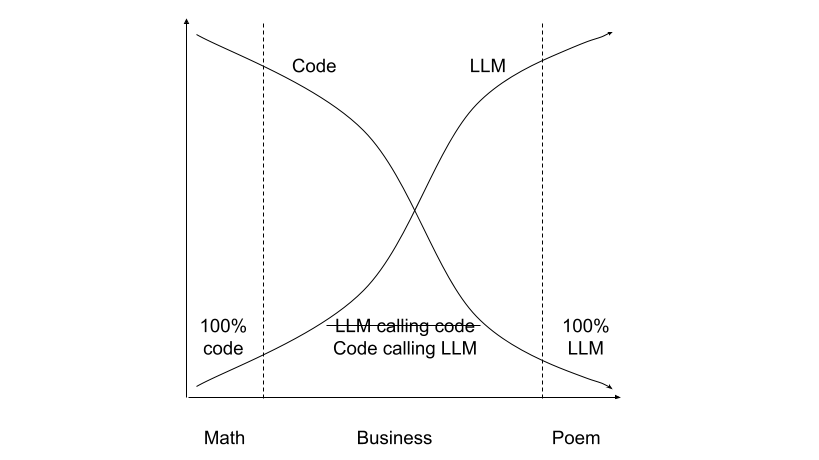
We are simply reverting back to the historical progression. Before LLMs, we had a largely deterministic computing world (~80% deterministic algorithms, ~20% probabilistic/heuristic methods). Then LLMs flipped this ratio: suddenly ~80% probabilistic (neural networks for everything) with ~20% deterministic (tool calls to calculators, databases).
This proposal simply restores the natural balance: deterministic algorithms as the foundation (~80%), calling probabilistic models as specialized tools (~20%) where their statistical nature is advantageous.
The components exist (ACE, graph transformers, AST parsers) but what's missing isn't technology; it's the willingness to admit that scaling has limits and architecture matters again.
Notes:
- You can find the GPT5 accuracy in FrontierMath (13.5% in no tools mode vs. 26.3% in python mode) on its launch blog.
- In one measurement, tool mode cost ~63× less; more conservatively we estimate tool-use may be 4×–10× cheaper for similar tasks in other settings.
- I don't have benchmarks comparing tree-based versus token-based code generation. I am speculating 35%-40% accuracy based on the theoretical advantages of preserving semantic structure and eliminating tokenization fragmentation. I plan to do a pilot study next, by finetuning on 100 structured examples to see if it actually helps.
Like
Comments · 1
Nov 12, 2025
got some interesting idea to test
Add your comment