

Last year, Boeing 787 crashed into a medical college in India killing 260 people. Investigators blame the pilots. The pilots' families blame Boeing and the final report has not been released. Meanwhile, US Department of War wants to use Anthropic’s AI model in fully autonomous weapons without human approval. Anthropic refused it, because their model is unreliable.
AI systems of today are nowhere near reliable enough to make fully autonomous weapons. Anyone who's worked with AI models understands that there's a basic unpredictability to them that in a purely technical way we have not solved.
— Dario Amodei, Anthropic CEO
The unreliability of AI models arises out of two problems:
AI is lossy: AI model breaks the input prompt into tokens (roughly equivalent to words). Then, its transformers reconstruct structure from fragments and loses accuracy in the process [1]. Due to this, the models can count characters incorrectly or generate wrong code. Now, they might kill innocent people in a small % of cases.
AI is a blackbox: When the model converts the broken-down tokens into an array of numbers (an embedding vector), we don't know what each of these numbers mean. Neither do we know how each of these numbers transforms into a different array of numbers as it goes through the layers of the neural network.
I have long argued that we have to reduce the loss in accuracy as much as possible. In this essay, we will see why solving the black box nature is equally important when it comes to life or death decisions like fully autonomous weapons or cancer detection.
Let's consider this prompt you might give an AI:
I have a mole on my upper chest. It's been there for years but it looks darker recently, with some brownish patches and a bluish spot on one side. Should I be worried?
An AI model might analyze this and output:
The color variation you describe, particularly the bluish area and uneven brown tones, warrants dermatological evaluation.
How did the model get there? What happened between "brownish patches" and "bluish spot" and the assessment that these colors could be an indication of cancer?
Understanding the Black Box
The model splits your prompt into tokens and converts each one into a vector of 4,096 floating-point numbers:
Tokens | Embedding vector |
I | [0.23, -0.45, 0.56, …] |
have | [0.43, -0.76, 0.12, …] |
… | |
brown | [0.52, -0.31, 0.43, …] |
ish | [0.11, 0.45, -0.08, …] |
… |
What does 0.52 in the first position of "brown" mean? Nobody knows. Not the engineers who built the model. Not the researchers who trained it. Every single dimension is unnamed.
These vectors are stacked into a matrix, roughly 50 × 4,096, about 200,000 unnamed numbers. This passes through ~96 transformer layers. Early layers learn syntax. Middle layers learn that "brownish" describes the mole color and that "one side" indicates asymmetry. Late layers combine color variation, asymmetry, and change over time into a risk assessment. Out comes the recommendation.
Dermatologists use the ABCDE rule: Asymmetry, Border, Color, Diameter, Evolving. Multiple colors within a single lesion is one of the strongest indicators of cancer. The model almost certainly learned this. But which of the 4,096 dimensions encodes "color variance within a lesion"? Nobody can say. The path from "brownish patches and a bluish spot" to "warrants evaluation" is invisible. For color identification that can be life or death, invisible is not good enough.
Anthropic can find brown color as feature
In May 2024, Anthropic published Scaling Monosemanticity. Using sparse autoencoders, they decomposed the internal activations of Claude 3 Sonnet into interpretable features. They found millions of recognizable patterns such as Golden Gate Bridge, code bugs, sycophantic praise etc. In our prompt, they can find “brown” as a feature. These features are a combination of dimensions. Hypothetically, these dimensions could be Red, Green, Blue. It could represent every color in the world as coordinates in 3 dimensional RGB axis. Brownish could be (165, 120, 60), bluish could be (40, 50, 120) and so on.
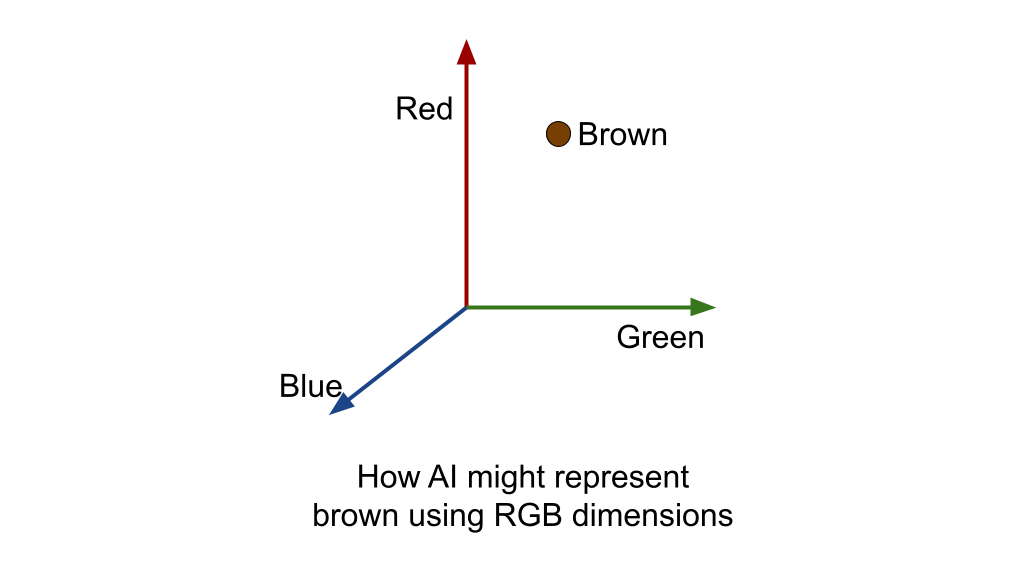
But, they did not find the dimensions i.e. the underlying axes such as Red, Green, and Blue. And they did it backwards. They trained unnamed dimensions first and let millions of features get packed into them via superposition. If the model was trained on colors based on CMYK, then its unnamed dimensions could represent CMYK instead of RGB. So, these dimension is Sonnet are still a mystery. But, what if we named the dimensions first?
Converting brown color into RGB
Two years before Anthropic's paper, researchers had already proved this was possible. In 2020, Şenel and colleagues at Koç University published a method that constrains embedding training so each dimension aligns with a named concept. During training, words associated with a concept are pushed to high values on that dimension. They found that naming the dimensions didn't hurt performance. The embeddings remained just as useful while becoming interpretable.
In 2022, the same group extended this with BiImp (bidirectional imparting). Each dimension encodes "abstract" in the positive direction and "concrete" in the negative direction. But, they didn't push naming down to the primitive level such as Red, Green and Blue.
RGB for every feature in the world
Both represent significant progress, but neither of them paint the full picture for interpretability:
Anthropic found features but from unnamed dimensions.
BiImp named dimensions but didn’t trace them to features.
The solution is to combine both: name the truly canonical and orthogonal dimensions, then let features emerge on top. Such dimensions already exist in the scientific literature. Color has 3 (Red, Green, Blue) from vision science. Taste has 5 (sweet, sour, salty, bitter, umami) from gustatory science. Emotion has 3 (valence, arousal, dominance) from psychology. Spatial dimensions from geometry. Sound from acoustics and so on [2]. This is a significant undertaking, but with such named dimensions, the diagnosis becomes fully traceable:
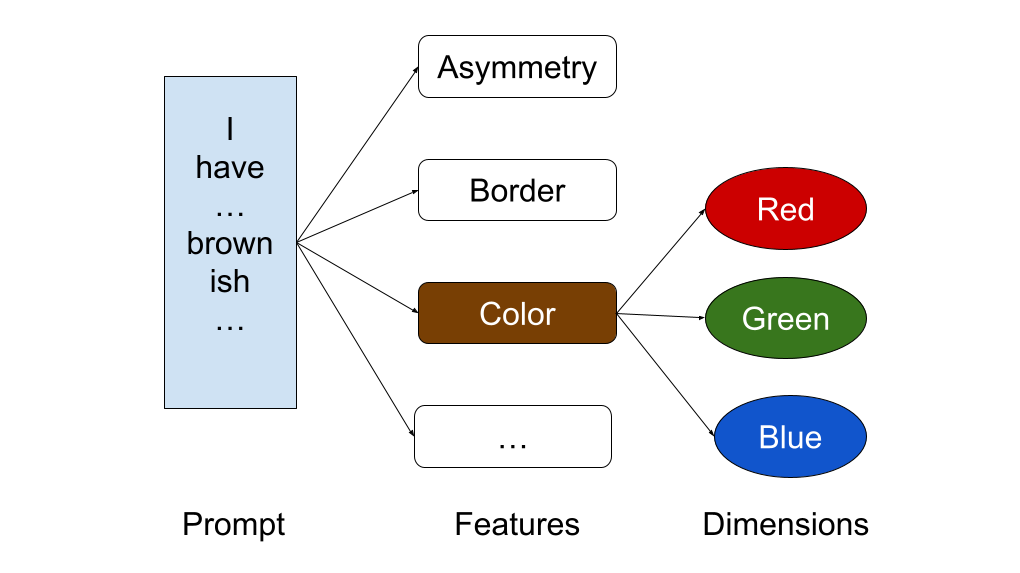
Now, if we run Anthropic's feature extraction on top, it might be readable by the construction of named dimensions. A doctor can see how the brownish color and asymmetric distribution are used in the AI's decision making process.
Graph transformer to convert graph embedding
Named dimensions will change the shape of the current embedding vector. The current flat array of 4,096 unnamed floats is a point in dense space. But, the new named dimensions is a sparse graph: each token is a node, each named dimension is a typed edge.
Brownish | Representation | |
Current | [0.52, -0.31, 0.43, ..., 0.19] | flat array |
Proposed | { blue: 0.24 } | sparse graph |
This graph embedding is the natural input for a graph transformer, where attention operates on typed edges between named nodes instead of matrix multiplications over floating point numbers.
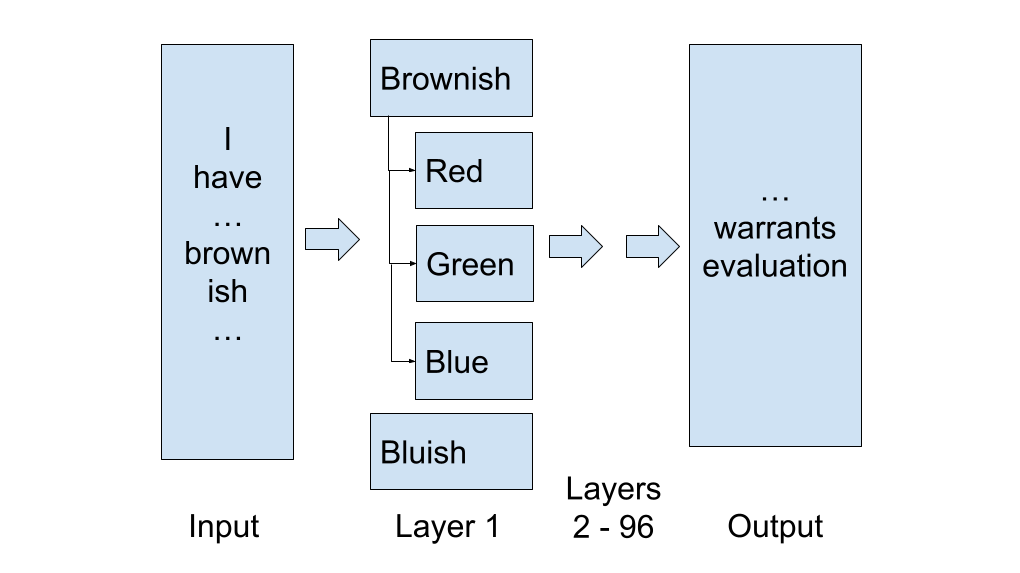
We can now trace the prompt into words, words into graphs of features/dimensions and see how each layer of the neural network transforms them into intermediate graphs till it reaches the answer. Incidentally, this graph transformer architecture can be used for improving accuracy. Both, interpretability and the losslessness are the two sides of the same architecture. Together, a graph embedding feeding a graph transformer, where every step from input to output is traceable.
Aftermath of a probabilistic error
Today, we don't have this traceability. So, Anthropic wants a human to be involved in the decision before the trigger is pulled. US Department of War, on the other hand, says someone will be accountable after the fact. With human approval, you can catch the model's error before acting. Without it, the person overseeing can blame the model. The model can show its chain of thought, but those are posthoc justification and reasoning models don't always say what they think:
- Model sometimes generate unfaithful chain of thought that contradicts their internal knowledge. When you give incorrect hints, they often construct elaborate yet flawed justifications.
- When given a hidden hint, Claude 3.7 Sonnet uses it to get the answer but only admits it 25% of the time. The other 75%, they make up a fake explanation.
- Models hide unethical behavior and actively conceal that they used stolen information while presenting clean looking reasoning.
Boeing builds aircraft with deterministic, traceable engineering. Every bolt has a specification. Every system has a flight data recorder. The technology is fully interpretable. And still, the final report is not yet released. Now imagine Anthropic's AI model making targeting decisions in fully autonomous weapons. If it’s wrong 1% of the time and it kills an innocent person, we at least owe an explanation and assure that the mistake won’t be repeated. Can we do that with LLM that is probabilistic, not deterministic?
Anthropic was right to draw the line today. But drawing the line is not enough. The model has to be interpretable in the days to come. The mole on your chest deserves that. So does the person on the other end of a drone strike.
Notes:
- The lossless argument is in Let AI Speak in Its Mother Tongue essay. The interpretability argument is in this essay. Both feed into the same architecture: graph embeddings for a graph transformer, where every step from input to output is traceable and no information is lost.
- Anna Wierzbicka's Natural Semantic Metalanguage identifies ~65 semantic primes found in every documented human language: SOMEONE, SOMETHING, GOOD, BAD, BIG, SMALL, THINK, WANT, DO, HAPPEN, BEFORE, AFTER, BECAUSE, IF. They appear in every language ever studied, from Mandarin to Yankunytjatjara.
1 likes
1 comments
Like
Mar 2, 2026
The DoW is in a hilarious predicament because they are absolutely clueless about how unpredictable and inaccurate today's state-of-the-art models are, particularly in complex reasoning. What they do best is language semantics and interception. Anthropic is being upfront and does what is expected of a responsible and ethical group.
Add your comment